深圳天安源投資咨詢 專業引領,賦能企業投資決策

在當今瞬息萬變、機遇與風險并存的經濟環境中,精準、前瞻的投資決策是企業實現跨越式發展的關鍵。作為扎根于中國創新前沿陣地——深圳的專業服務機構,深圳天安源投資咨詢有限公司憑借其深厚的行業積淀、專業的人才團隊與全面的服務體系,正成為眾多企業與投資者信賴的合作伙伴,為客戶的資本增值與戰略布局提供堅實支撐。
一、 立足深圳,輻射全國的專業力量
深圳,作為粵港澳大灣區的核心引擎之一,匯聚了海量的科技創新企業、活躍的資本市場以及開放的經濟政策。天安源投資咨詢深耕于此,深刻理解本地及全國市場的運行規律、產業動態與政策導向。公司專注于為各類企業(包括初創公司、成長型企業及成熟集團)以及高凈值投資者,提供一站式、定制化的投資咨詢服務,業務范圍覆蓋股權投資、并購重組、財務顧問、盡職調查、投資可行性研究、估值分析及投后管理等多個關鍵環節。
二、 核心服務領域與專業價值
- 投資策略與規劃:基于對宏觀經濟、行業趨勢及客戶自身資源的深入分析,協助客戶制定清晰、可行的中長期投資戰略與資產配置方案,明確投資方向與風險偏好。
- 項目盡職調查與評估:在股權投資、并購等交易前,進行財務、法律、業務及技術等多維度的深度盡職調查,獨立、客觀地評估目標項目的潛在價值、風險隱患與發展前景,為交易定價與決策提供關鍵依據。
- 交易結構設計與財務顧問:參與復雜的并購、重組或融資交易,設計最優的稅務、法律及財務交易結構,協調各方資源,主導談判進程,保障客戶利益最大化并控制交易風險。
- 投后管理與價值提升:投資并非終點。天安源提供系統的投后管理支持,協助投資者監控被投企業運營,參與公司治理,并嫁接戰略資源、管理經驗與資本市場渠道,助力被投企業成長,實現投資價值的持續提升。
- 市場研究與可行性分析:針對特定行業、區域市場或具體項目,提供深度的市場研究報告與投資可行性分析,幫助客戶洞察先機,規避盲區,科學決策。
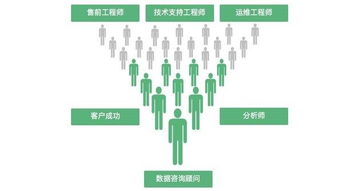
三、 專業團隊與核心優勢
天安源投資咨詢的核心優勢在于其匯聚了一支兼具國際視野與本土實戰經驗的精英團隊。團隊成員多來自知名金融機構、投資銀行、會計師事務所及產業龍頭,具備扎實的金融、財務、法律及行業專業知識。公司堅持“獨立、客觀、嚴謹、創新”的服務理念,恪守職業道德,確保所有建議與分析都建立在充分的數據與理性的判斷之上。
憑借在深圳及大灣區的長期深耕,公司建立了廣泛而有效的企業網絡、投資人網絡及中介機構合作關系,能夠為客戶高效對接資金、項目與產業資源,創造超越咨詢本身的價值。
四、 賦能客戶,共創未來
無論是尋求融資擴張的科技新銳,意圖進行產業整合的行業巨頭,還是希望優化資產配置的個人投資者,深圳天安源投資咨詢都致力于成為其最值得信賴的“外腦”與伙伴。通過提供高度專業、貼近需求的解決方案,天安源助力客戶在復雜的市場環境中撥開迷霧,把握確定性機遇,有效管理風險,最終實現資產的穩健增值與企業的可持續發展。
在充滿挑戰與機遇的新經濟時代,專業的投資咨詢服務已從“可選”變為“剛需”。深圳天安源投資咨詢正以專業的姿態,持續賦能企業決策,與客戶攜手,洞見共創價值。
如若轉載,請注明出處:http://www.enjoyuk.com.cn/product/70.html
更新時間:2026-06-18 12:31:48